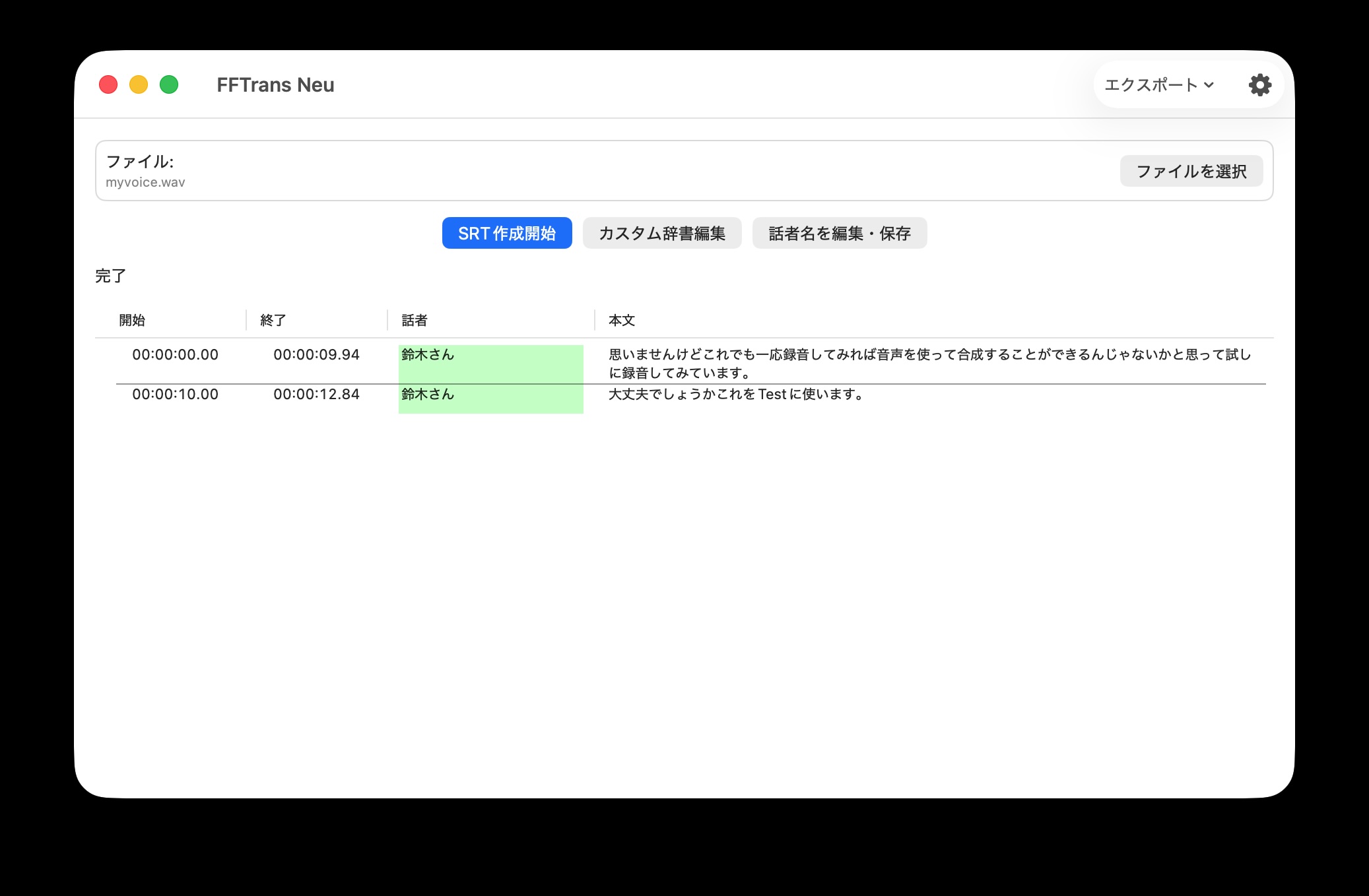
CoreML対応で軽量かつ完全オフライン(初回のモデルダウンロードを除く)な話者分離・長時間対応文字起こしアプリ「FFTrans Neu」を作りました。
公式な機能面などは製品ページに任せるとして、こちらには作成中の苦労話や今後の展開などを交えて書いてみようかなと。
以前からずっとSwiftで作りたいなというのはあったのですが、話者分離をする手段がなくて機会を伺っていたというのが正直なところです。
WWDCでAppleも次期OSあたりでSpeaker Diarizationに対応すると発表されたようですが、FFTransの場合、「Speaker 1」、「Speaker 2」みたいな話者分離だけでなく、一度登録した話者を最初から「鈴木さん」みたいに名前で表示させたいのでembeddingを取得できる必要もあるため、より敷居が高いんですよね。
FluidAudioに「embedding extraction」があるおかげで実現できたといっても過言ではありません。
ただ音声認識のほうはParakeetベースでは多言語対応が難しいので、そこはWhisperKitという合わせ技になっています。
ちなみにFFTrans ProはPythonとPyannote Audio、mlx-whisperでできていて、FFmpeg依存の排除などで結構手間がかかりました。
FFTrans Proをリリースしたのが昨年8月ですが、開発はたしか7月初頭くらいからだったと思います。
今回は先月末くらいにスタートして実質2週間くらいでリリースできていますが、実際にはその前に手掛けてきたノウハウやライブラリがあってのことなので、多少は迅速になったかなという程度です。
案外とヘルプだとかOSSライセンス表記、英語リソース対応などの細かいところで手間取るのは相変わらずですね。
バイブコーディングもある程度活用していますけど、正直、Swiftの最新のシンタックスから外れていたり、FluidAudioやWhisperKitの最新版の情報を持っていなかったりもするため、壁打ち方式を取ることが多い感じです。
画面周りとか、ファイルのドラッグ&ドロップ対応など、ちょっとしたことで引っ掛かった時には助けられる(逆に足を引っ張られる)こともありますが。
まずはFluidAudioとWhisperKitで簡易構築から始めてきましたが、これまで通りのLarge-V3を使うとメモリも消費するし、速度はFFTrans Proより遅くなってしまいました。
メモリ解放をしていないテスト段階ではありますが、10GBくらい消費していて、結局ここは話者分離が終わったらモデルをアンロードし、文字起こしが終わったらこちらもアンロードという形で双方が同時にメモリに居座ることがないようにしました。
またNeural Engineを使うため、mlxのようにメモリにキャッシュされた状態が保持されづらいため、チャンク処理によるディスパッチやメモリ転送のオーバーヘッドは増えがちです。
話者ごとに音声をまとめてから投げるという手もあるのですが、それをやるとタイムラインが徐々にズレたり、ハルシネーションが増えやすくなるなどの弊害もあります。
そこで今回も同一話者で話間が指定時間以内のものをまとめてTranscribeし、結果のセグメントを元のタイムラインにフィットさせるProと同様の手法を取りました。
それでも6分の音声で2分30秒とか掛かっていて、色々なモデルを試した結果、Large-V3の量子化モデルなら50秒程度にできることがわかりました。
この量子化モデルも本来なら何かあってもCPUに自動的にフォールバックされるはずが、なぜか固まってしまうため、GPUと協業させる形で折り合いを付けました。
まだチャンクバッチでTranscribeするといった方法もありますけど、M1の8GBから安定して動作させることを考えるとシンプルな処理のほうが無難だろうと、現状は判断しています。
参考までにモデルによる文字起こし時間の違いを挙げておきます。(Mac Studio M2 Maxにて6分音声)
large-v3-v20240930_626MB ANE : 48秒58
large-v3-v20240930_626MB GPU : 1分7秒52
large-v3 ANE : 2分36秒
Medium ANE : 1分24秒90
(参考:FFTrans Pro(Large-V3) : 1分17秒)
もうひとつ、Proからの移行の課題は句読点補完でした。
ProはBERTを用いてやっていますが、まずはNaturalLanguageを使って自前で補完してみました。
間違わないように配慮するとあまりうまくいかず、量子化で句読点が付きづらくなるのも相まってそこはまだ少し不満です。
Foundation Modelsを使ってやる方法も実装してありますが、こっちは勝手に本文を変えてしまう癖が完全には抜けず、本文改ざんがない場合だけ採用するようにしていますし、やはりCPUパワーやメモリ消費も増えがちなのでオフが推奨です。
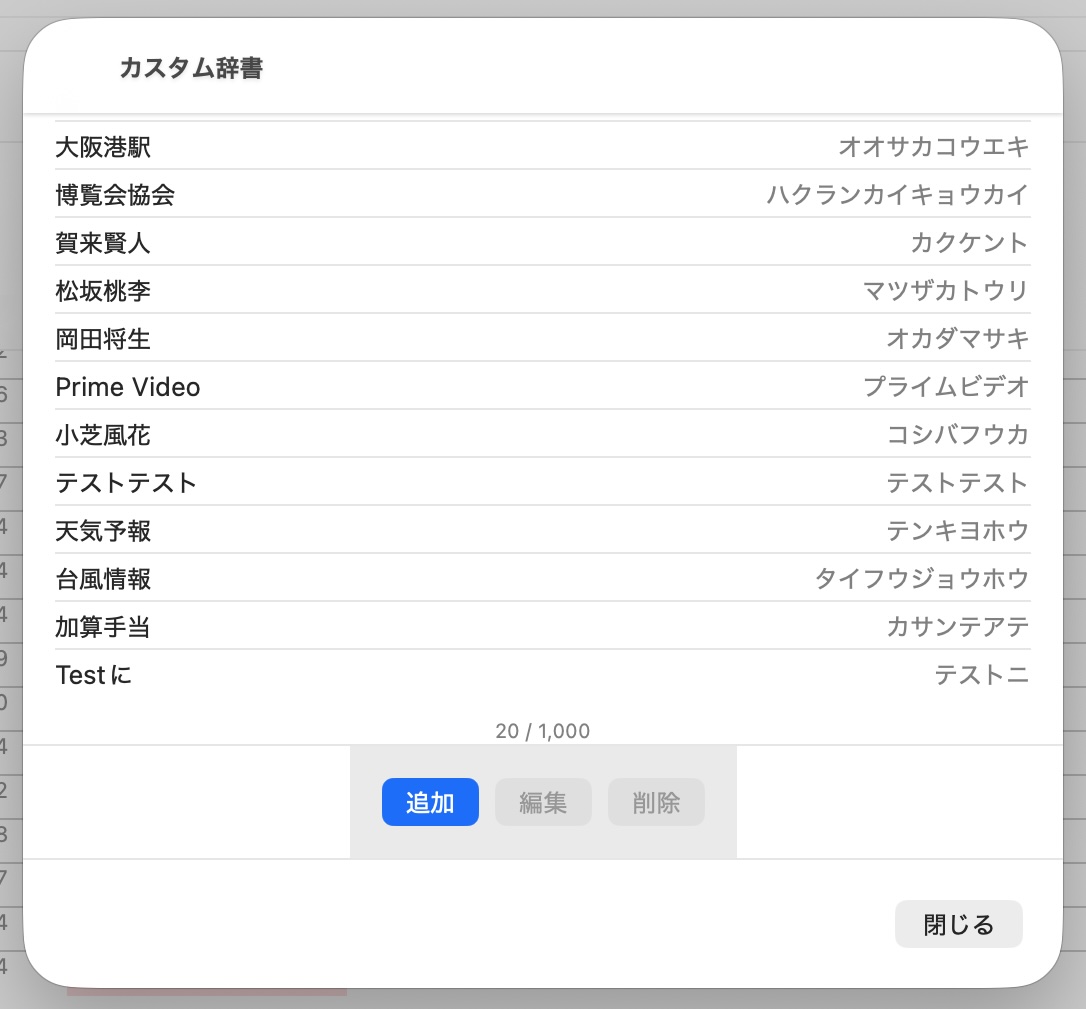
カスタム辞書はまだ速度向上の余地はあるものの、ほぼPro並みの機能が実装できています。
半角文字を読みに使える形にしてあるので、柔軟性も向上しているはずです。
将来的には同音異義語の選択手法も考えてみたいと思っています。
ハルシネーションフィルターや音声から言語識別して間違った言語に誤認識したり速度低下を防ぐ処理もProと同様に搭載してあります。
むしろ細かい部分はProより処理が洗練されているところもあるくらいです。
それでも量子化も含めた微妙な精度低下でタイムラインがズレがちだったり、話者の精度はDSR搭載のProには及ばないなどありますけど、そこはProとの差別化ポイントでもあるでしょう。
Proで苦労した体験版の部分はアプリのサイズが極小にできたおかげで、もう製品版のまま試してもらう形を取りました。
文字起こしした結果テキストの保存だけはできませんが、それ以外はフル機能を試してもらえるようにしてあります。
もちろん文字起こしに使用するモデルも時間制限も一切ありません。
性能とご自身のマシンで体感してもらって購入いただけるのはやっぱり良いですね。
販売方法に関してはApp Storeとだいぶ悩みましたが、結果的にはStripe決済でライセンスファイルをメール送付する従来形態のままとしました。
先ほどの体験版を別途用意しなくて良いという点と、モデルダウンロード以外は完全オフラインを堅持したいというのがあっての形です。
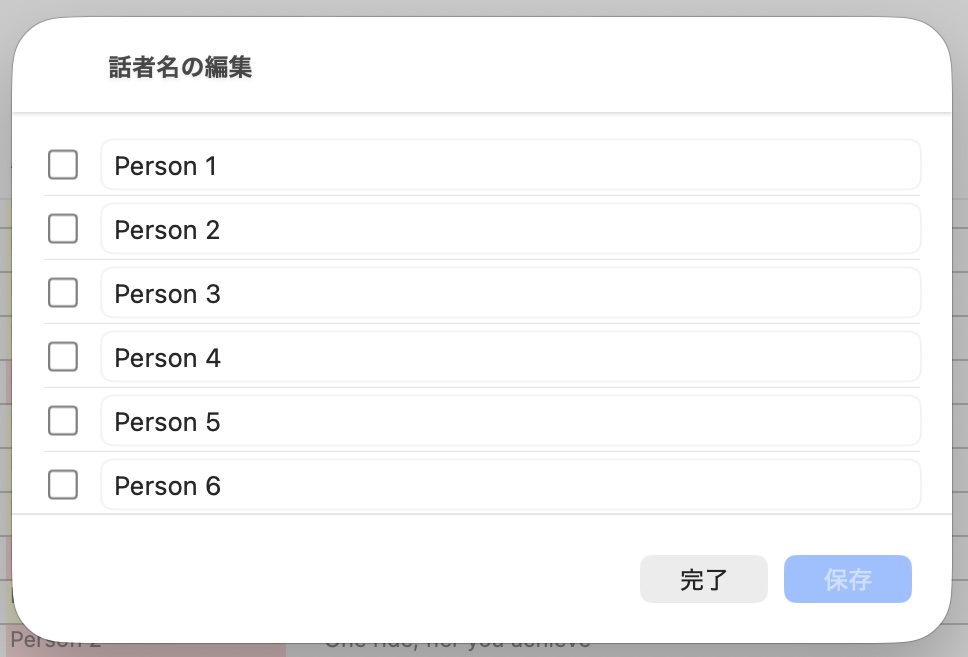
他にも登録する話者を選択できるようにしたり、SRT編集もある程度可能にするなど、廉価版という形にはしてありません。
もちろん今後もバージョンアップを重ねて改良していく予定で、編集機能のさらなる強化や、完了時の通知機能、カスタム辞書の高速化などを検討しています。
並行してもう次のアプリのアイデアも浮かんでいるので、そちらの製作にも取り掛かるつもりではいますが、そこはもうマンパワー次第という感じです。

コメント